Hi All,
Paul asked me to start a discussion on the role of the InfoManager in the OpenHIE architecture. There are several aspects to this discussion and perhaps it is good to have a review of the CSD functionality.
Let’s start with the CSD perspective of what the Info Manager is supposed to do which is:
- Periodically refreshes cached content from one or more Services Directory actors. A Service Directory actor is a source of data on one or more of the four CSD entities: health workers, health facilities, organizations and services.
- Executes the inbound queries from Service Finder against its cached content and returns a response document in reply.
This is done against a common data model, expressed in XML, and which we can call a “CSD document” for simplicity. The inbound queries are the “stored queries” as well as the ad-hoc queries. In the CSD standard, there are required four stored queries each centered around the four main entities. In addition to the four required stored queries, CSD allows for an InfoManager to be optionally enhanced with new stored queries.
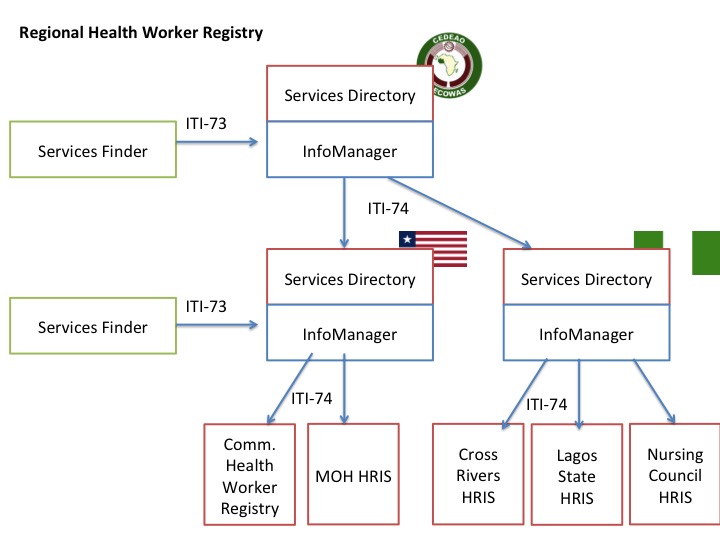
Restating this from the perspective of OpenHIE documented workflow with the “Facility Registry” and a “Health Worker Registry”, we have:
- the InfoManager requests from the FR shares updates to its CSD document
- the InfoManager requests from the HWR shares its CSD documents
- the InfoManager merges (interlinks) these two CSD documents together into a unified CSD document and answer inbound queries from the Interoperability Layer. This is the Interlinked Registry.
In short, the InfoManager actor is supposed to bring together multiple CSD data sources into a unified "CSD document” and allow querying against those. The requirements of an InfoManager actor are a bit broader than those of the corresponding OpenHIE workflow as CSD makes no distinction between a FR and a HWR. The OpenHIE reference implementation of the InfoManager actor, OpenInfoMan, supports these broader CSD requirements.
These broader requirements allow for, in particular, a federated view of data. Let’s take the particular example of the HWR in Nigeria. From the simplest perspective, each state has an HRIS system that serves as a source of health worker data. The HWR of Nigeria is essentially nothing more that an InfoManager actor which merges these state CSD documents together to allow for querying against a national registry of health workers. This federated support is built into the core OpenInfoMan software as one of it’s added stored queries. In fact, the OpenInfoMan supports federation of all four of the main entities (health workers, facilities, organization, and services) as there is only one line of code needed to support each one and it would have been silly not to support this.
One way to try to understand the Nigeria HWR example, and the OpenHIE FR+HWR example, is that they are both two cases of federation. The first is federation of health worker data by state, the second is a federation by entity. Both of these cases are handled simultaneously by the OpenInfoMan reference application.
These examples of federation only require two tiers in it’s federation. However, there are examples such as DATIM or WAHO where a federation at three or more tiers would be useful — e.g. sub-national, national, regional/global. Luckily, the OpenInfoMan application can already handle multi-tiered federation. This is because OpenInfoMan is not only a InfoManager actor but a Service Directory as well. Thus a regional (or global) InfoManager actor can ask each of the national registries (which act as both the InfoManager and Service Directory) actors for their updates to the national CSD documents.
We have only so far touched upon the facility and health worker entities in CSD. There are two other ones: organization and service. The concept of an organization in CSD has a couple of useful features:
- A facility can be associated to an organization
- A health worker can be associated to an organization
- An organization can be associated to another organization in a parent-child relationship
As a CSD organization is not limited to a “legal entities which are service delivery organizations” we can (and do) encode useful things in the CSD organization: - the geographic hierarchy under which a facility operates
- an collection of facilities that are operated by an FBO or MOH
- the facilities supported by/reportable on for a funding mechanism (represented as an organization)
We can save talking about services until another time, but they are pretty useful too
There is one other notable thing that the OpenInfoMan reference application does, and that is to support some basic terminology services. There are two main ways:
- There are terminologies referenced in the CSD data model (such as health worker cadre, facility type, type of contact points (e.g. email, phone, fax), etc.). To facilitate the sharing of these terminologies, OpenInfoMan acts as a Value Set Repository according to IHE’s Sharing Value Sets (SVS) profile. This is essentially a way to ask for an xml list defining a simple value set.
- There are some things in the CSD data model which would be useful to represent as a terminology - for example the organizational hierarchy of facilities. There is some nascent support to represent this as a FHIR Value Set, although this was more exploratory work and will need to be updated to see where the TS community lands on representing hierarchies.
I should also say what the InfoMan and the CSD InfoManager actor are not. It is not supposed to be a business domain application. Rather, it is the Service Directories that should be considered in general as the business domain systems — in the process of doing supporting their business processes, they generate useful data that needs to be merged into an “InterLinked Registry.” Such business domain systems could be: - A logistics or supply chain system which gathers and maintains information about warehouses and medical stores
- A professional council license and registration systems which collects information about health worker qualifications
- A HR Management system captures information about health worker deployment
- An HMIS, as part of reporting on service delivery, collects information about clinical facilities in a country
Cheers,
-carl